
大数据处理计算模式和系统
MapReduce计算模式的出现有力推动了大数据技术和应用的发展,使其成为目前大数据处理最成功的主流大数据计算模式。然而,现实世界中的大数据处理问题复杂多样,难以有一种单一的计算模式能涵盖所有不同的大数据计算需求。研究和实际应用中发现,由于MapReduce主要适合于进行大数据线下批处理,在面向低延迟和具有复杂数据关系和复杂计算的大数据问题时有很大的不适应性。因此,近几年来学术界和业界在不断研究并推出多种不同的大数据计算模式。
所谓大数据计算模式,是指根据大数据的不同数据特征和计算特征,从多样性的大数据计算问题和需求中提炼并建立的各种高层抽象(Abstraction)和模型(Model)。传统的并行计算方法主要从体系结构和编程语言的层面定义了一些较为底层的抽象和模型,但由于大数据处理问题具有很多高层的数据特征和计算特征,因此大数据处理需要更多地结合其数据特征和计算特性考虑更为高层的计算模式。
根据大数据处理多样性的需求,目前出现了多种典型和重要的大数据计算模式。与这些计算模式相适应,出现了很多对应的大数据计算系统和工具,如表1-1所示。
表1-1 大数据计算模式及其对应的典型系统和工具
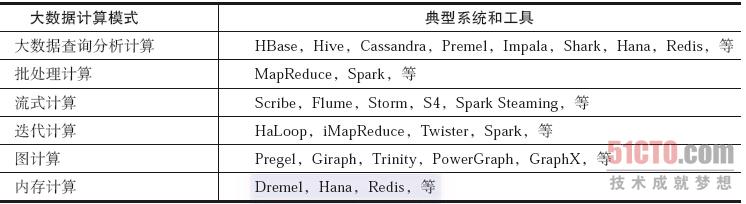
1.大数据查询分析计算模式与典型系统
由于行业数据规模的增长已大大超过了传统的关系数据库的承载和处理能力,因此,目前需要尽快研究并提供面向大数据存储管理和查询分析的新的技术方法和系统,尤其要解决在数据体量极大时如何能够提供实时或准实时的数据查询分析能力,满足企业日常的管理需求。然而,大数据的查询分析处理具有很大的技术挑战,在数量规模较大时,即使采用分布式数据存储管理和并行化计算方法,仍然难以达到关系数据库处理中小规模数据时那样的秒级响应性能。
大数据查询分析计算的典型系统包括hadoop下的HBase和Hive、Facebook公司开发的Cassandra、Google公司的 Dremel、Cloudera公司的实时查询引擎Impala;此外为了实现更高性能的数据查询分析,还出现了不少基于内存的分布式数据存储管理和查询系统,如Apache Spark下的数据仓库Shark、SAP公司的Hana、开源的Redis等。
2.批处理计算模式与典型系统
最适合于完成大数据批处理的计算模式是MapReduce,这是MapReduce设计之初的主要任务和目标。MapReduce是一个单输入、两阶段(Map和Reduce)的数据处理过程。首先,MapReduce对具有简单数据关系、易于划分的大规模数据采用“分而治之”的并行处理思想;然后将大量重复的数据记录处理过程总结成Map和Reduce两个抽象的操作;最后MapReduce提供了一个统一的并行计算框架,把并行计算所涉及到的诸多系统层细节都交给计算框架去完成,以此大大简化了程序员进行并行化程序设计的负担。
MapReduce的简单易用性使其成为目前大数据处理最成功的主流并行计算模式。在开源社区的努力下,开源的Hadoop系统目前已成为较为成熟的大数据处理平台,并已发展成一个包括众多数据处理工具和环境的完整的生态系统。目前几乎国内外的各个著名IT企业都在使用Hadoop平台进行企业内大数据的计算处理。此外,Spark系统也具备批处理计算的能力。
3.流式计算模式与典型系统
流式计算是一种高实时性的计算模式,需要对一定时间窗口内应用系统产生的新数据完成实时的计算处理,避免造成数据堆积和丢失。很多行业的大数据应用,如电信、电力、道路监控等行业应用以及互联网行业的访问日志处理,都同时具有高流量的流式数据和大量积累的历史数据,因而在提供批处理计算模式的同时,系统还需要能具备高实时性的流式计算能力。流式计算的一个特点是数据运动、运算不动,不同的运算节点常常绑定在不同的服务器上。
Facebook的Scribe和Apache的Flume都提供了一定的机制来构建日志数据处理流图。而更为通用的流式计算系统是Twitter公司的Storm、Yahoo公司的S4以及Apache Spark Steaming。
4.迭代计算模式与典型系统
为了克服Hadoop MapReduce难以支持迭代计算的缺陷,工业界和学术界对Hadoop MapReduce进行了不少改进研究。HaLoop把迭代控制放到MapReduce作业执行的框架内部,并通过循环敏感的调度器保证前次迭代的 Reduce输出和本次迭代的Map输入数据在同一台物理机上,以减少迭代间的数据传输开销;iMapReduce在这个基础上保持Map和Reduce 任务的持久性,规避启动和调度开销;而Twister在前两者的基础上进一步引入了可缓存的Map和Reduce对象,利用内存计算和pub/sub网络进行跨节点数据传输。
目前,一个具有快速和灵活的迭代计算能力的典型系统是Spark,其采用了基于内存的RDD数据集模型实现快速的迭代计算。
5.图计算模式与典型系统
社交网络、Web链接关系图等都包含大量具有复杂关系的图数据,这些图数据规模很大,常常达到数十亿的顶点和上万亿的边数。这样大的数据规模和非常复杂的数据关系,给图数据的存储管理和计算分析带来了很大的技术难题。用MapReduce计算模式处理这种具有复杂数据关系的图数据通常不能适应,为此,需要引入图计算模式。
大规模图数据处理首先要解决数据的存储管理问题,通常大规模图数据也需要使用分布式存储方式。但是,由于图数据具有很强的数据关系,分布式存储就带来了一个重要的图划分问题(Graph Partitioning)。根据图数据问题本身的特点,图划分可以使用“边切分”和“顶点切分”两种方式。在有效的图划分策略下,大规模图数据得以分布存储在不同节点上,并在每个节点上对本地子图进行并行化处理。与任务并行和数据并行的概念类似,由于图数据并行处理的特殊性,人们提出了一个新的“图并行”(Graph Parallel)的概念。事实上,图并行是数据并行的一个特殊形式,需要针对图数据处理的特征考虑一些特殊的数据组织模型和计算方法。
目前已经出现了很多分布式图计算系统,其中较为典型的系统包括Google公司的Pregel、Facebook对Pregel的开源实现 Giraph、微软公司的Trinity、Spark下的GraphX,以及CMU的GraphLab以及由其衍生出来的目前性能最快的图数据处理系统 PowerGraph。
6.内存计算模式与典型系统
Hadoop MapReduce为大数据处理提供了一个很好的平台。然而,由于MapReduce设计之初是为大数据线下批处理而设计的,随着数据规模的不断扩大,对于很多需要高响应性能的大数据查询分析计算问题,现有的以Hadoop为代表的大数据处理平台在计算性能上往往难以满足要求。随着内存价格的不断下降以及服务器可配置的内存容量的不断提高,用内存计算完成高速的大数据处理已经成为大数据计算的一个重要发展趋势。例如,Hana系统设计者总结了很多实际的商业应用后发现,一个提供50TB总内存容量的计算集群将能够满足绝大多数现有的商业系统对大数据的查询分析处理要求,如果一个服务器节点可配置 1TB~2TB的内存,则需要25~50个服务器节点。目前Intel Xeon E-7系列处理器最大可支持高达1.5TB的内存,因此,配置一个上述大小规模的内存计算集群是可以做到的。


