
面向大规模数据处理,MapReduce有以下三个层面上的基本设计思想。
1.对付大数据并行处理:分而治之
一个大数据若可以分为具有同样计算过程的数据块,并且这些数据块之间不存在数据依赖关系,则提高处理速度的最好办法就是采用“分而治之”的策略进行 并行化计算。MapReduce采用了这种“分而治之”的设计思想,对相互间不具有或者有较少数据依赖关系的大数据,用一定的数据划分方法对数据分片,然 后将每个数据分片交由一个节点去处理,最后汇总处理结果。
2.上升到抽象模型:Map与Reduce
(1)Lisp语言中的Map和Reduce
MapReduce借鉴了函数式程序设计语言Lisp的设计思想。Lisp是一种列表处理语言。它是一种应用于人工智能处理的符号式语言,由MIT的人工智能专家、图灵奖获得者John McCarthy于1958年设计发明。
Lisp定义了可对列表元素进行整体处理的各种操作,如:
- (add#(1 2 3 4)#(4 3 2 1))将产生结果:#(5 5 5 5)
Lisp中也提供了类似于Map和Reduce的操作,如:
- (map'vector#+#(1 2 3 4)#(4 3 2 1))
通过定义加法map运算将两个向量相加产生与前述add运算同样的结果#(5 5 5 5)。
进一步,Lisp也可以定义reduce操作进行某种归并运算,如:
- (reduce#'+#(1 2 3 4))通过加法归并产生累加结果10。
(2)MapReduce中的Map和Reduce
MPI等并行计算方法缺少高层并行编程模型,为了克服这一缺陷,MapReduce借鉴了Lisp函数式语言中的思想,用Map和Reduce两个函数提供了高层的并行编程抽象模型和接口,程序员只要实现这两个基本接口即可快速完成并行化程序的设计。
与Lisp语言可以用来处理列表数据一样,MapReduce的设计目标是可以对一组顺序组织的数据元素/记录进行处理。现实生活中,大数据往往是 由一组重复的数据元素/记录组成,例如,一个Web访问日志文件数据会由大量的重复性的访问日志构成,对这种顺序式数据元素/记录的处理通常也是顺序式扫 描处理。图1-13描述了典型的顺序式大数据处理的过程和特征:
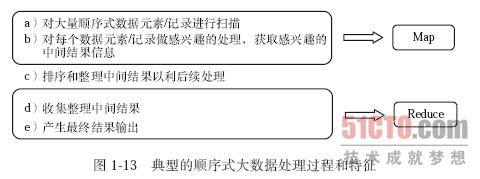
MapReduce将以上的处理过程抽象为两个基本操作,把上述处理过程中的前两步抽象为Map操作,把后两步抽象为Reduce操作。于是Map 操作主要负责对一组数据记录进行某种重复处理,而Reduce操作主要负责对Map的中间结果进行某种进一步的结果整理和输出。以这种方 式,MapReduce为大数据处理过程中的主要处理操作提供了一种抽象机制。
3.上升到构架:以统一构架为程序员隐藏系统层细节
MPI等并行计算方法缺少统一的计算框架支持,程序员需要考虑数据存储、划分、分发、结果收集、错误恢复等诸多细节;为此,MapReduce设计 并提供了统一的计算框架,为程序员隐藏了绝大多数系统层面的处理细节,程序员只需要集中于应用问题和算法本身,而不需要关注其他系统层的处理细节,大大减 轻了程序员开发程序的负担。
MapReduce所提供的统一计算框架的主要目标是,实现自动并行化计算,为程序员隐藏系统层细节。该统一框架可负责自动完成以下系统底层相关的处理:
1)计算任务的自动划分和调度。
2)数据的自动化分布存储和划分。
3)处理数据与计算任务的同步。
4)结果数据的收集整理(sorting,combining,partitioning,等)。
5)系统通信、负载平衡、计算性能优化处理。
6)处理系统节点出错检测和失效恢复。


