
1.基本组成结构与文件访问过程
HDFS是一个建立在一组分布式服务器节点的本地文件系统之上的分布式文件系统。HDFS采用经典的主-从式结构,其基本组成结构如图3-1所示。
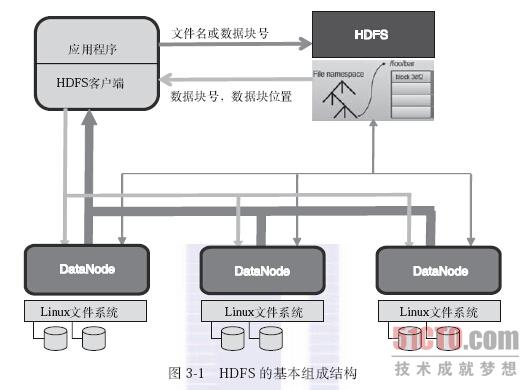
一个HDFS文件系统包括一个主控节点NameNode和一组DataNode从节点。NameNode是一个主服务器,用来管理整个文件系统的命名空间和元数据,以及处理来自外界的文件访问请求。NameNode保存了文件系统的三种元数据:1)命名空间,即整个分布式文件系统的目录结构;2)数据块与文件名的映射表;3)每个数据块副本的位置信息,每一个数据块默认有3个副本。
HDFS对外提供了命名空间,让用户的数据可以存储在文件中,但是在内部,文件可能被分成若干个数据块。DataNode用来实际存储和管理文件的数据块。文件中的每个数据块默认的大小为64MB;同时为了防止数据丢失,每个数据块默认有3个副本,且3个副本会分别复制在不同的节点上,以避免一个节点失效造成一个数据块的彻底丢失。
每个DataNode的数据实际上是存储在每个节点的本地Linux文件系统中。
在NameNode上可以执行文件操作,比如打开、关闭、重命名等;而且NameNode也负责向DataNode分配数据块并建立数据块和 DataNode的对应关系。DataNode负责处理文件系统用户具体的数据读写请求,同时也可以处理NameNode对数据块的的创建、删除副本的指令。
NameNode和DataNode对应的程序可以运行在廉价的普通商用服务器上。这些机器一般都运行着GNU/Linux操作系统。HDFS由 Java语言编写,支持JVM的机器都可以运行NameNode和DataNode对应的程序。虽然一般情况下是GNU/Linux系统,但是因为 Java的可移植性,HDFS也可以运行在很多其他平台之上。一个典型的HDFS部署情况是:NameNode程序单独运行于一台服务器节点上,其余的服务器节点,每一台运行一个DataNode程序。
在一个集群中采用单一的NameNode可以大大简化系统的架构。另外,虽然NameNode是所有HDFS的元数据的唯一所有者,但是,程序访问文件时,实际的文件数据流并不会通过NameNode传送,而是从NameNode获得所需访问数据块的存储位置信息后,直接去访问对应的 DataNode获取数据。这样设计有两点好处:一是可以允许一个文件的数据能同时在不同DataNode上并发访问,提高数据访问的速度;二是可以大大减少NameNode的负担,避免使得NameNode成为数据访问瓶颈。
HDFS的基本文件访问过程是:
1)首先,用户的应用程序通过HDFS的客户端程序将文件名发送至NameNode。
2)NameNode接收到文件名之后,在HDFS目录中检索文件名对应的数据块,再根据数据块信息找到保存数据块的DataNode地址,将这些地址回送给客户端。
3)客户端接收到这些DataNode地址之后,与这些DataNode并行地进行数据传输操作,同时将操作结果的相关日志(比如是否成功,修改后的数据块信息等)提交到NameNode。
2.数据块
为了提高硬盘的效率,文件系统中最小的数据读写单位不是字节,而是一个更大的概念——数据块。但是,数据块的信息对于用户来说是透明的,除非通过特殊的工具,否则很难看到具体的数据块信息。
HDFS同样也有数据块的概念。但是,与一般文件系统中大小为若干KB的数据块不同,HDFS数据块的默认大小是64MB,而且在不少实际部署中,HDFS的数据块甚至会被设置成128MB甚至更多,比起文件系统上几个KB的数据块,大了几千倍。
将数据块设置成这么大的原因是减少寻址开销的时间。在HDFS中,当应用发起数据传输请求时,NameNode会首先检索文件对应的数据块信息,找到数据块对应的DataNode;DataNode则根据数据块信息在自身的存储中寻找相应的文件,进而与应用程序之间交换数据。因为检索的过程都是单机运行,所以要增加数据块大小,这样就可以减少寻址的频度和时间开销。
3.命名空间
HDFS中的文件命名遵循了传统的“目录/子目录/文件”格式。通过命令行或者是API可以创建目录,并且将文件保存在目录中;也可以对文件进行创建、删除、重命名操作。不过,HDFS中不允许使用链接(硬链接和符号链接都不允许)。命名空间由NameNode管理,所有对命名空间的改动(包括创建、删除、重命名,或是改变属性等,但是不包括打开、读取、写入数据)都会被HDFS记录下来。
HDFS允许用户配置文件在HDFS上保存的副本数量,保存的副本数称作“副本因子”(Replication Factor),这个信息也保存在NameNode中。
4.通信协议
作为一个分布式文件系统,HDFS中大部分的数据都是通过网络进行传输的。为了保证传输的可靠性,HDFS采用TCP协议作为底层的支撑协议。应用可以向NameNode主动发起TCP连接。应用和NameNode交互的协议称为Client协议,NameNode和DataNode交互的协议称为 DataNode协议(这些协议的具体内容请参考其他资料)。而用户和DataNode的交互是通过发起远程过程调用(Remote Procedure Call,RPC)、并由NameNode响应来完成的。另外,NameNode不会主动发起远程过程调用请求。
5.客户端
严格来讲,客户端并不能算是HDFS的一部分,但是客户端是用户和HDFS通信最常见也是最方便的渠道,而且部署的HDFS都会提供客户端。
客户端为用户提供了一种可以通过与Linux中的Shell类似的方式访问HDFS的数据。客户端支持最常见的操作如(打开、读取、写入等);而且命令的格式也和Shell十分相似,大大方便了程序员和管理员的操作。具体的命令行操作详见3.4节。
除了命令行客户端以外,HDFS还提供了应用程序开发时访问文件系统的客户端编程接口,具体的HDFS编程接口详见3.5节。


