
随着BIG DATA大数据概念逐渐升温,如何搭建一个能够采集海量数据的架构体系摆在大家眼前。如何能够做到所见即所得的无阻拦式采集、如何快速把不规则页面结构化并存储、如何满足越来越多的数据采集还要在有限时间内采集。这篇文章结合我们自身项目经验谈一下。
我们来看一下作为人是怎么获取网页数据的呢?
- 打开浏览器,输入网址url访问页面内容。
- 复制页面内容的标题、作者、内容。
- 存储到文本文件或者excel。
从技术角度来说整个过程主要为 网络访问、扣取结构化数据、存储。我们看一下用java程序如何来实现这一过程。
- import java.io.IOException;
- import org.apache.commons.httpclient.HttpClient;
- import org.apache.commons.httpclient.HttpException;
- import org.apache.commons.httpclient.HttpStatus;
- import org.apache.commons.httpclient.methods.GetMethod;
- import org.apache.commons.lang.StringUtils;
- public class HttpCrawler {
- public static void main(String[] args) {
- String content = null ;
- try {
- HttpClient httpClient = new HttpClient();
- //1、网络请求
- GetMethod method = new GetMethod("http://www.baidu.com" );
- int statusCode = httpClient.executeMethod(method);
- if (statusCode == HttpStatus. SC_OK) {
- content = method.getResponseBodyAsString();
- //结构化扣取
- String title = StringUtils.substringBetween(content, "<title>" , "</title>" );
- //存储
- System. out .println(title);
- }
- } catch (HttpException e) {
- e.printStackTrace();
- } catch (IOException e) {
- e.printStackTrace();
- } finally {
- }
- }
- }
通 过这个例子,我们看到通过httpclient获取数据,通过字符串操作扣取标题内容,然后通过system.out输出内容。大家是不是感觉做 一个爬虫也还是蛮简单呢。这是一个基本的入门例子,我们再详细介绍怎么一步一步构建一个分布式的适用于海量数据采集的爬虫框架。
整个框架应该包含以下部分,资源管理、反监控管理、抓取管理、监控管理。看一下整个框架的架构图:
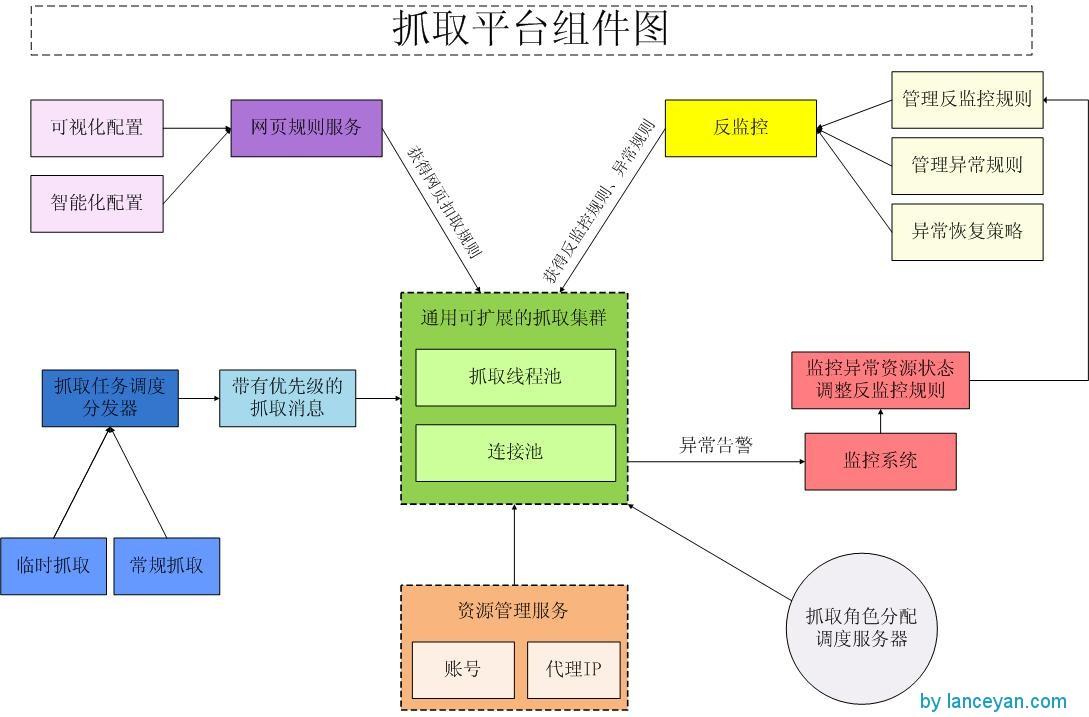
- 资源管理指网站分类体系、网站、网站访问url等基本资源的管理维护;
- 反监控管理指被访问网站(特别是社会化媒体)会禁止爬虫访问,怎么让他们不能监控到我们的访问时爬虫软件,这就是反监控机制了
一 个好的采集框架,不管我们的目标数据在哪儿,只要用户能够看到都应该能采集到。所见即所得的无阻拦式采集,无论是否需要登录的数据都能够顺利采 集。现在大部分社交网站都需要登录,为了应对登录的网站要有模拟用户登录的爬虫系统,才能正常获取数据。不过社会化网站都希望自己形成一个闭环,不愿意把 数据放到站外,这种系统也不会像新闻等内容那么开放的让人获取。这些社会化网站大部分会采取一些限制防止机器人爬虫系统爬取数据,一般一个账号爬取不了多 久就会被检测出来被禁止访问了。那是不是我们就不能爬取这些网站的数据呢?肯定不是这样的,只要社会化网站不关闭网页访问,正常人能够访问的数据,我们也 能访问。说到底就是模拟人的正常行为操作,专业一点叫“反监控”。
那一般网站会有什么限制呢?
一定时间内单IP访问次数,没有哪个人会在一段持续时间内过快访问,除非是随意的点着玩,持续时间也不会太长。可以采用大量不规则代理IP来模拟。
一定时间内单账号访问次数,这个同上,正常人不会这么操作。可以采用大量行为正常的账号,行为正常就是普通人怎么在社交网站上操作,如果一个人一天24小时都在访问一个数据接口那就有可能是机器人了。
如 果能把账号和IP的访问策略控制好了,基本可以解决这个问题了。当然对方网站也会有运维会调整策略,说到底这是一个战争,躲在电脑屏幕后的敌我双 方,爬虫必须要能感知到对方的反监控策略进行了调整,通知管理员及时处理。未来比较理想应该是通过机器学习算法自动完成策略调整,保证抓取不间断。
- 抓取管理指通过url,结合资源、反监控抓取数据并存储;我们现在大部分爬虫系统,很多都需要自己设定正则表 达式,或者使用htmlparser、jsoup等软件来硬编码解决结构化抓取的问题。不过大家在做爬虫也会发现,如果爬取一个网站就去开发一个类,在规 模小的时候还可以接受,如果需要抓取的网站成千上万,那我们不是要开发成百上千的类。为此我们开发了一个通用的抓取类,可以通过参数驱动内部逻辑调度。比 如我们在参数里指定抓取新浪微博,抓取机器就会调度新浪微博网页扣取规则抓取节点数据,调用存储规则存储数据,不管什么类型最后都调用同一个类来处理。对 于我们用户只需要设置抓取规则,相应的后续处理就交给抓取平台了。
整个抓取使用了 xpath、正则表达式、消息中间件、多线程调度框架(参考)。xpath 是 一种结构化网页元素选择器,支持列表和单节点数据获取,他的好处可以支持规整网页数据抓取。我们使用的是google插件 XPath Helper,这个玩意可以支持在网页点击元素生成xpath,就省去了自己去查找xpath的功夫,也便于未来做到所点即所得的功能。正则表达式补充xpath抓取不到的数据,还可以过滤一些特殊字符。消息中间件,起到抓取任务中间转发的目的,避免抓取和各个需求方耦合。比如各个业务系统都可能抓取数据,只需要向消息中间件发送一个抓取指令,抓取平台抓完了会返回一条消息给消息中间件,业务系统在从消息中间件收到消息反馈,整个抓取完成。多线程调度框架之前提到过,我们的抓取平台不可能在同一时刻只抓一个消息的任务;也不可能无限制抓取,这样资源会耗尽,导致恶性循环。这就需要使用多线程调度框架来调度多线程任务并行抓取,并且任务的数量,保证资源的消耗正常。
不管怎么模拟总还是会有异常的,这就需要有个异常处理模块,有些网站访问一段时间需要输入验证码,如果不处理后续永远返回不了正确数据。我们需要有机制能够处理像验证码这类异常,简单就是有验证码了人为去输入,高级一些可以破解验证码识别算法实现自动输入验证码的目的。
扩展一下 :所见即所得我们是不是真的做到?规则配置也是个重复的大任务?重复网页如何不抓取?
1、有些网站利用js生成网页内容,直接查看源代码是一堆js。 可以使用mozilla、webkit等可以解析浏览器的工具包解析js、ajax,不过速度会有点慢。
2、网页里有一些css隐藏的文字。使用工具包把css隐藏文字去掉。
3、图片flash信息。 如果是图片中文字识别,这个比较好处理,能够使用ocr识别文字就行,如果是flash目前只能存储整个url。
4、一个网页有多个网页结构。如果只有一套抓取规则肯定不行的,需要多个规则配合抓取。
5、html不完整,不完整就不能按照正常模式去扣取。这个时候用xpath肯定解析不了,我们可以先用htmlcleaner清洗网页后再解析。
6、 如果网站多起来, 规则配置这个工作量也会非常大。如何帮助系统快速生成规则呢?首先可以配置规则可以通过可视化 配置,比如用户在看到的网页想对它抓取数据,只需要拉开插件点击需要的地方,规则就自动生成好了。另在量比较大的时候可视化还是不够的,可以先将类型相同 的网站归类,再通过抓取的一些内容聚类,可以统计学、可视化抓取把内容扣取出几个版本给用户去纠正,最后确认的规则就是新网站的规则。这些算法后续再讲。 这块再补充一下(多谢zicjin建议):
背景: 如果我们需要抓取的网站很多,那如果靠可视化配置需要耗费大量的人力,这是个成本。并且这个交给不懂html的业务去配置 准确性值得考量,所以最后还是需要技术做很多事情。那我们能否通过技术手段可以帮助生成规则减少人力成本,或者帮助不懂技术的业务准确的把数据扣取下来并 大量复制。
方案: 先对网站分类,比如分为新闻、论坛、视频等,这一类网站的网页结构是类似的。在业务打开需要扣取的还没有录入我们规则库的 网页时,他先设定这个页面的分类(当然这个也可以机器预先判断,他们来选择,这一步必须要人判断下),有了分类后,我们会通过“统计学、可视化判断”识别 这一分类的字段规则,但是这个是机器识别的规则,可能不准确,机器识别完后,还需要人在判断一下。判断完成后,最后形成规则才是新网站的规则
7、对付重复的网页,如果重复抓取会浪费资源,如果不抓需要一个海量的去重判断缓存。判断抓不抓,抓了后存不存,并且这个缓存需要快速读写。常见的做法有bloomfilter、相似度聚合、分类海明距离判断。
- 监控管理指不管什么系统都可能出问题,如果对方服务器宕机、网页改版、更换地址等我们需要第一时间知道,这时监控系统就起到出现了问题及时发现并通知联系人。
目前这 样的框架搭建起来基本可以解决大量的抓取需求了。通过界面可以管理资源、反监控规则、网页扣取规则、消息中间件状态、数据监控图表,并且可以 通过后台调整资源分配并能动态更新保证抓取不断电。不过如果一个任务的处理特别大,可能需要抓取24个小时或者几天。比如我们要抓取一条微博的转发,这个 转发是30w,那如果每页线性去抓取耗时肯定是非常慢了,如果能把这30w拆分很多小任务,那我们的并行计算能力就会提高很多。不得不提的就是把大型的抓 取任务hadoop化,废话不说直接上图:
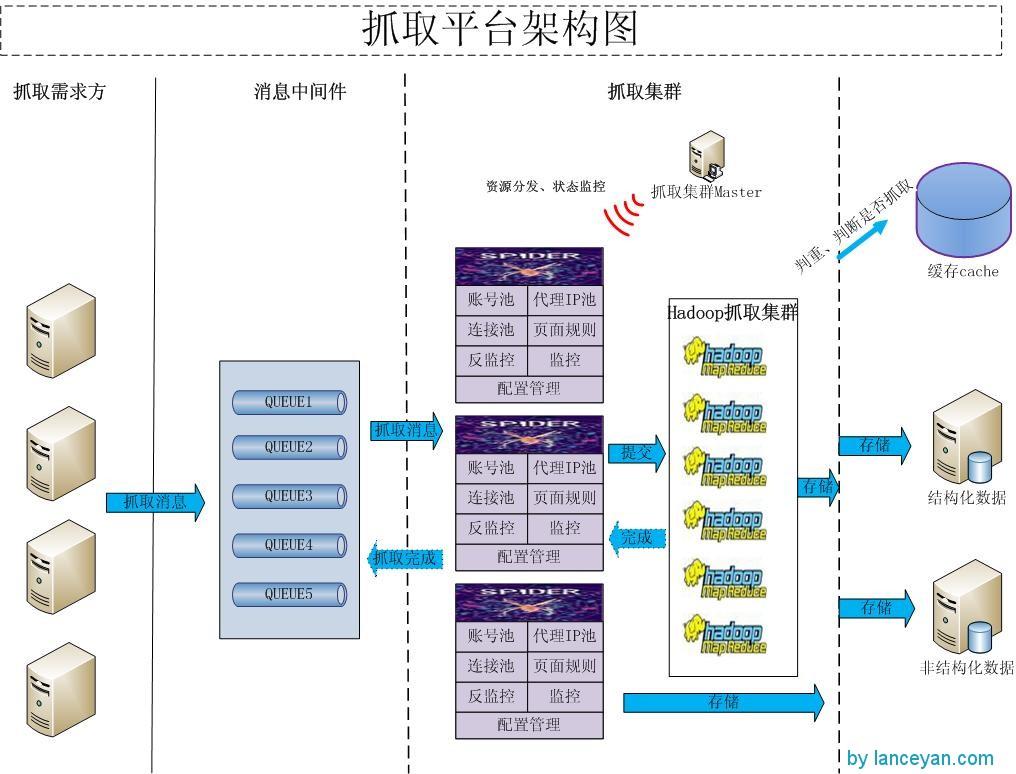
今天先写到这里,后续再介绍下 日均千万大型采集项目实战。
原文链接:http://developer.51cto.com/art/201308/408387.htm


