
大数据处理模型MapReduce
大数据时代生产的数据最终是需要进行计算的,存储的目的也就是为了做大数据分析。通过计算、分析、挖掘数据背后的东西,才是大数据的意义所在。hadoop不仅提供了数据存储的分布式文件系统,更重要的是提供了分布式编程模型和分布式计算系统,通过该编程模型和分布式计算架构可以解决大数据时代所面临的数据处理问题。该分布式计算模型、架构就是大名鼎鼎的Mapreduce。Mapreduce同样来自于Google,2004年Google发表了著名的Mapreduce论文,然后被Hadoop的前身项目采纳。Mapreduce分布式计算模型应用于Google的数据搜索、数据挖掘业务中,因此,目前很多互联网企业都采用mapreduce的思路进行大数据处理。
Mapreduce计算模型将数据的计算过程分成两个阶段:一个阶段是Map,另一个是reduce,并且,这两个阶段可以进行串联组合。因此,采用Mapreduce编程模型可以将一个算法分解成Map函数和Reduce函数。Map函数对输入数据进行分布式并行操作;reduce函数对map函数的结果进行合并操作,并且输出结果数据。Mapreduce的运行模型如下图所示:
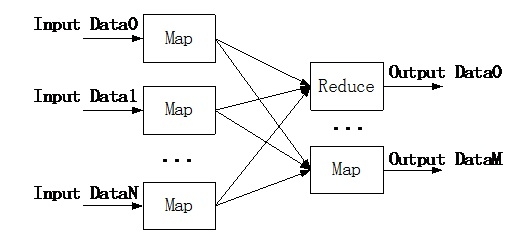
Mapreduce是一种分布式编程模型,为了支持这种编程模型,Hadoop项目实现了计算任务的分发、调度、运行和容错机制。Mapreduce的运行框架如下图所示:
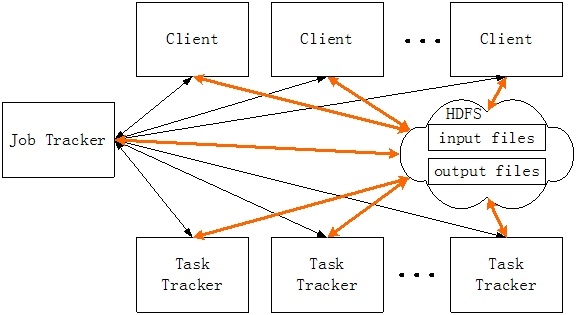
在分布式计算模型中,主要有两个角色,第一个角色是Job Tracker;另一个角色是Task Tracker。Job Tracker的主要任务是负责协调Mapreduce作业的执行,具体是任务的调度、分发。Job Tracker是Mapreduce计算架构中的主控节点。Task Tracker用来执行Job Tracker分配的任务,具体包括Map任务和Reduce任务。因此,Task Tracker可以被分成Map Task Tracker和Reduce Task Tracker。Job Tracker在整个框架中的地位很重要,并且时刻保持和Task Tracker之间的联系,一旦发现Task Tracker出现了故障,那么Job Tracker会在其他节点上对fail的任务进行重新调度。另外,考虑到计算任务需要从数据库或者文件系统中获取数据,因此,在Job Tracker在调度一个任务的时候,需要考虑计算节点和数据源的距离。通常可以将计算任务直接在存储节点上调度,这样可以避免网络上的数据传输,降低IO数据传输引入的延迟。
十几年前,存储发展到一定规模的时候,提出了存储和计算的模型,从而使得存储技术独立发展,形成SAN和NAS这样的大型存储系统。在大数据计算的时代,存储和计算的无情分离也会带来负面影响,导致计算性能下降,因此,计算和存储的一体化对mapreduce框架下的大数据分析显得很有价值。其实,是否分离不是重点,关键在于系统结构需要满足应用需求。SAN、NAS这样的存储网络往往需要通过高速互连技术(FC/IB/10Gb以太网)与计算Server相连,这样可以降低IO延迟。在大数据环境下,为了降低成本,这种高速互连未必是最佳选择。因此,在以成本为导向的分布式架构中,计算和存储一体化将是一个不错的选择。
下面来简单描述一下在mapreduce架构下如何进行分布式计算:
1)当一个Client需要进行计算处理时,需要向Job Tracker提交一个计算作业。并且将作业以文件的形式存放在HDFS中。
2)Job Tracker是计算资源的调度器,根据一定的策略首先将Client提交的Map任务调度到Task Tracker上。
3)Map任务会在多个Task Tracker上并发执行。计算的中间结果会以文件的形式存储到HDFS上。
4)当Map任务都执行完成之后,Job Tracker再分配Reduce任务到task tracker服务器上。
5)当所有的reduce任务全部执行完成之后,计算结果会输出到Hadoop文件系统中。
从这个过程可以看出,Job Tracker类似于CPU资源调度器;Task Tracker是CPU资源;数据的输入输出都基于Hadoop文件系统。
从这个架构可以看出,整个系统的计算节点具有很强的可扩展性,其唯一的潜在瓶颈点在于Job Tracker。并且单一的Job Tracker也会成为一个单点故障点。和分布式文件系统类似,Job Tracker的地位和NameNode是一样的,一旦Job Tracker发生故障,那么整个计算系统将无法正常运行。因此,采用这种架构的分布式计算系统设计重点在于Job Tracker。首先需要保证Job Tracker具有很强的事务处理能力;其次需要保证Job Tracker具有很强的高可用性。
上述的分布式计算系统只是一种计算工具,要想真正实现分布式数据处理,在编程模型上同样需要采用Mapreduce的思路,特别在算法设计上需要采用Mapreduce的模型。所有的算法需要分解成Map和Reduce的两类方法,并且这些方法可以并发执行。在数据挖掘领域有一些mapreduce的开源算法资源,例如mahout项目就是一个很有代表性的开源资源库。
本文出自 “存储之道” 博客,请务必保留此出处http://alanwu.blog.51cto.com/3652632/1418021


